
RCMBnet — A distributed Hardware and Firmware Support for Sofware Fault Tolerance
Design, formal verification and implementation of a hardware support for the consistent execution of fault-tolerant software that follows the N-Version Programming approach.
Software is a major source of reliability degradation in dependable systems. One of the classical remedies is to provide tolerance to software faults by using N-Version Programming (NVP). However, due to the necessity of independent development of N versions for the same application program, the requirements on special hardware and the need for changes and additions at all levels of the system, NVP solutions are very costly and therefore seldom used.
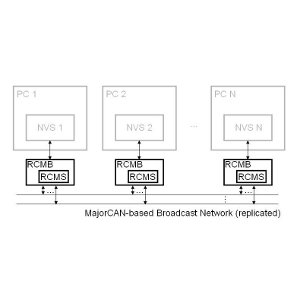
In a previous work, a low-cost architecture for NVP execution was devised, in which each of the N versions is executed on a different standard computer. A special hardware unit, called NVXP, is attached to each computer to take care of the communication among versions and of all tasks required to support the execution of the NVP application. Some of the key features of this architecture are: the broadcast network that links the NVXPs together is duplicated in order to prevent a single point of failure; off-the-shelf components are used and the fault tolerance functionality is concentrated into the NVXP being thereby orthogonal to the other functionalities of the system.
In this dissertation, we present a complete redesign of the above-mentioned architecture, that aims at ensuring its actual implementability and at resolving the potential inconsistent states that were not treated in detail in the original design.
We have made the following three main changes in the hardware of this architecture. First, we have developed a completely new and improved design for the NVXPs, which we call Redundancy and Communication Management Boards (RCMBs). The set of RCMBs connected to each other by means of the broadcast network is what we call the RCMBnet. Second, in order to further reduce the cost of the final system, we have chosen PCs as platforms for executing the different versions, in such a way that the RCMBs are PC boards inserted in the bus of the host PCs. And third, we use the Controller Area Network (CAN) protocol as the basic communication technology for the broadcast network, due to its well-known advantages related to cost, reliability and real-time performance, and due to the growing interest in using CAN for critical applications. In fact what we use is a modification to the CAN protocol, called MajorCAN, which we have devised to eliminate some scenarios of inconsistent communication that CAN exhibits.
Besides introducing changes in the hardware, we have designed a new software to be executed in the RCMBs. Two aspects of this software concerning the consistent management of the redundancy have received a special attention in this dissertation: replica determinism enforcement of all replicated operations and consistent reintegration of RCMBs after suffering transient faults. Replica determinism enforcement ensures, for instance, that all non-faulty versions produce the same results even if some versions are faulty. On the other hand, reintegration prevents a quick attrition of the available redundancy by allowing an RCMB that has experienced a temporary failure to return to the normal coordinated operation with the other RCMBs. The new mechanism proposed for consistent reintegration has been formally verified using model checking.
Given that our ultimate goal is as complex as providing the design of a complete fault-tolerant distributed system, we have made a significant effort to keep an approach as systematic as possible. More specifically, we have adopted the guidelines provided by the paradigm proposed by Prof. Avizienis for the design of fault-tolerant systems. Following one of said guidelines, we have developed first prototypes for the essential parts of the architecture, thus giving support to our claim of actual implementability.
Our design exhibits relevant differences with other architectures which were conceived for similar purposes. Moreover, our approach presents significant advantages beyond the fulfillment of its initial aims of low cost, actual implementability and consistent operation. Some of these additional advantages are that it achieves a consistent management of the redundancy without introducing a sizeable computation or communication overhead in the system; it requires less computers and versions to tolerate a fixed number of faults than common distributed systems and it allows the broadcast network to use a simplified topology such as a bus, thereby facilitating scalability. Finally, although initially developed for NVP, our RCMBnet is also able to support other software replication techniques, such as active replication.
Project Leader

Project Collaborators
-
Photo
José Miró
Related Publications
-
RCMBnet: A distributed Hardware and Firmware Support for Software Fault Tolerance
-
Improving the Safety of AUVs
MTS/IEEE Oceans
-
A double CAN architecture for fault-tolerant control systems
International CAN Conference (ICC)
-
A CAN hub with Improved Error Detection and Isolation
International CAN Conference (iCC)
-
Pushing error containment and fault tolerance
CAN Newsletter. Special Edition on Automotive Networks
-
Experimental assessment of ReCANcentrate, a replicated star topology for CAN
SAE 2006 Transactions Journal of Passenger Cars: Electronic and Electrical Systems
-
Combining Operational Flexibility and Dependability in FTT-CAN
IEEE Transactions on Industrial Informatics
-
An Active Star Topology for Improving Fault Confinement in CAN Networks
IEEE Transactions on Industrial Informatics
-
Managing redundancy in CAN-based networks supporting N-Version Programming
Computer Standards and Interfaces
-
Modeling and Verification of Master/Slave Clock Synchronization Using Hybrid Automata and Model-Checking
International Conference on Formal Engineering Methods (ICFEM, LNCS 4789)
-
Modelling MajorCAN with UPPAAL
IEEE International Conference on Emerging Technologies and Factory Automation (ETFA)
-
First results of the assessment of the improvement of error containment achieved by CANcentrate
IEEE International Workshop on Factory Communication Systems (WFCS)
-
An UPPAAL Model for Formal Verification of Master/slave Clock Synchronization over the Controller Area Network
IEEE International Workshop on Factory Communication Systems (WFCS)
-
Towards analyzing the fault-tolerant operation of Server-CAN
IEEE Conference on Emerging Technologies and Factory Automation (ETFA)
-
Using UPPAAL to Model and Verify a Clock Synchronization Protocol for the Controller Area Network
IEEE Conference on Emerging Technologies and Factory Automation (ETFA)
-
Position Paper on Dependability and Reconfigurability in Distributed Embedded Systems
International Workshop on Real-Time Networks (RTN)
-
ReCANcentrate: A replicated star topology for CAN networks
IEEE Conference on Emerging Technologies and Factory Automation (ETFA)
-
Design and Modeling of a Protocol to Enforce Consistency among Replicated Masters in FTT-CAN
IEEE International Workshop on Factory Communication Systems (WFCS)
-
CANcentrate: An Active Star Topology for CAN Networks
IEEE International Workshop on Factory Communication Systems (WFCS)
-
Clock Synchronization in CAN Distributed Embedded Systems
International Workshop on Real-Time Networks (RTN)
-
COTS-based Hardware Support to Timeliness in CAN Networks
IEEE International Conference on Emerging Technology and Factory Automation (ETFA)
-
Harmonizing Dependability and Real Time in CAN Networks
Second International Workshop on Real-Time LANs in the Internet Age (RTLIA)
-
An Architecture for Physical Injection of Complex Fault Scenarios in CAN Networks
IEEE International Conference on Emerging Technology and Factory Automation (ETFA)
-
Enforcing Consistency of Communication Requirements Updates in FTT-CAN
International Workshop on Dependable Embedded Systems (DES)
-
Automatic Inspection of Underwater Environments by Means of a Fleet of Submersible Agents
Pattern Recognition Advances in Iberoamerica
-
Design and Implementation of a Redundancy Manager for Triple Redundant CAN Controllers
Annual Conference of the IEEE Industrial Electronics Society (IECON)
-
Hardware Support for Fault Tolerance in Triple Redundant CAN Controllers
IEEE International Conference on Electronics, Circuits and Systems (ICECS)
-
RAO: A Low-Cost AUV for Testing
MTS/IEEE Oceans
-
MajorCAN: A modification to the Controller Area Network protocol to achieve Atomic Broadcast
First International Workshop on Group Communications and Computations (IWGCC)
-
Incorporating A Safety Hardware Module On A Low-Cost AUV
International Symposium on Robotics and Automation (ISRA)
-
A Cost-Effective Hardware Architecture for Fail-Safe Autonomous Underwater Vehicles
IEEE International Conference on Electronics, Circuits and Systems (ICECS)
-
A low-cost fail-safe circuit for fault-tolerant control systems
IEEE International Conference on Electronics, Circuits and Systems (ICECS)
-
Consistent management and slow attrition of redundancy in a distributed hardware support for NVP execution
First International Conference on Dependable Systems and Networks (ICDSN)
-
A technique to analyse the tolerance to transient overloads of a fault-tolerant real-time system
IEEE High Accurance Systems Engineering Workshop (HASE)
-
Fixed priority schedulability analysis of a distributed real-time fault-tolerant architecture
International Conference on Parallel and Distributed Techniques and Applications (PDPTA)
-
Un circuito de bajo coste para la tolerancia a fallos en sistemas de control industrial
Seminario Anual de Automática, Electrónica Industrial e Instrumentación (SAAEI)
-
Redundancy Management in a Low-Cost Distributed Hardware and Firmware Support for Software-Fault Tolerance
-
An UPPAAL Model for Formal Verification of Clock Synchronization over CAN
-
On the Management of Media Replication in ReCANcentrate
-
Enhancing the response of ReCANcentrate in presence of faults
-
On the Design of a Clock Service for CAN Networks
-
Una descripción de los fundamentos del protocolo TTCAN diseñado por Bosch
-
System Partitioning of a Low-Cost Distributed Hardware and Firmware Support for Software-Fault Tolerance
-
Design and implementation of CANcentrate: an active star topology for improving fault confinement in CAN networks
-
Hardware Design of a High-Precision and Fault-Tolerant Clock Subsystem for CAN Networks
IFAC International Conference on Fieldbus Systems and their Applications (FET)
-
Analyzing Atomic Broadcast in TTCAN Networks
IFAC International Conference on Fieldbus Systems and their Applications (FET)
-
An Orthogonal and Fault-Tolerant Subsystem for High-Precision Clock Synchronization in CAN Networks
WSEAS International Conference on Signal Processing, Robotics and Automation (ISPRA)